

DOI Seite / Zitierlink:
https://doi.org/10.11588/diglit.1167#0297




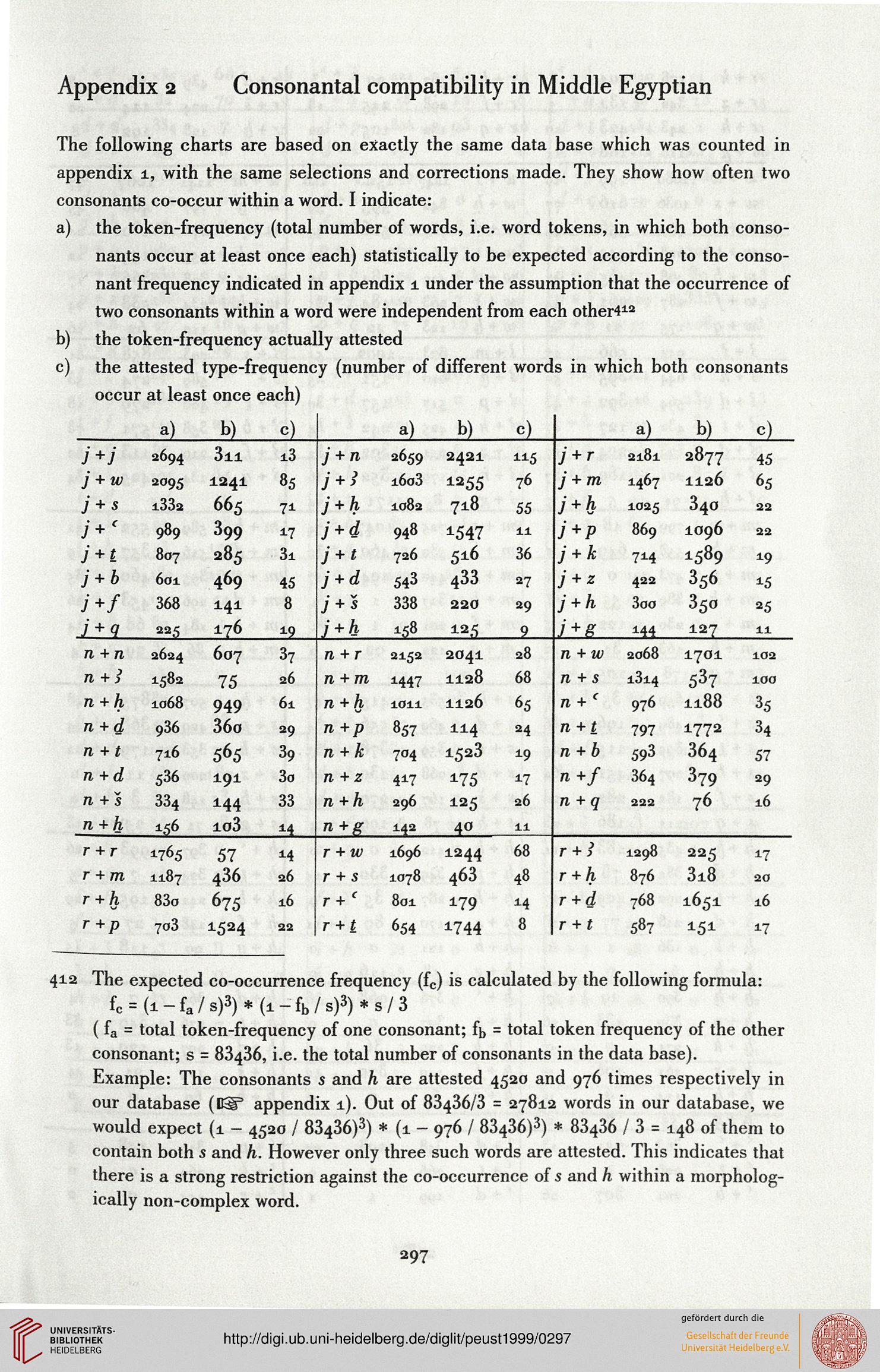
Appendix 2 Consonantal compatibility in Middle Egyptian
The following charts are based on exactly the same data base which was counted in
appendix 1, with the same selections and corrections made. They show how often two
consonants co-occur within a word. I indicate:
a) the token-frequency (total number of words, i.e. word tokens, in which both conso-
nants occur at least once each) statistically to be expected according to the conso-
nant frequency indicated in appendix 1 under the assumption that the occurrence of
two consonants within a word were independent from each other412
b) the token-frequency actually attested
c) the a
ttested
type-frequency (number of different words in which both consonants
occur at least once each)
a)
b)
°)
»)
b)
<=)
*)
*>)
c)
j+j
2694
3n
±3
j + 71
2659
2421
"5
j + r
2181
2877
45
j + w
2095
1241
85
j + 1
i6o3
1255
76
j + m
1467
1126
65
j + s
±33a
665
71
j + h
1082
718
55
j + h
1025
340
22
/+'
989
39o
17
j + d
948
1547
11
J+P
869
1096
22
j + t
807
285
3i
j + t
726
5*6
36
j + k
7*4
1589
19
j+b
601
469
45
j + d
543
433
27
j + z
422
356
15
j+f
368
141
8
j + s
338
220
29
j + h
3oo
350
25
i + q
225
176
19
j + h
**■
125
9
i*n
144
127
11
n + n
2624
607
37
n + t
2152
2041
28
n + w
2068
1701
102
n + J
1582
75
26
n + m
M47
1128
68
n + s
i3i4
537
100
n + h
1068
949
61
n + h
1011
1126
65
n + c
976
1188
35
n + d
936
36o
29
n + p
857
114
24
n + t
797
1772
34
n +1
716
565
39
n + k
704
1523
19
n + b
593
364
57
n + d
536
191
3o
n + z
417
*75
17
n+f
364
379
29
n + s
334
144
33
n + h
296
125
26
n + q
222
76
16
n + h
*fl6
io3
M
n+g
142
40
11
r + r
1765
57
14
r + w
1696
1244
68
r + l
1298
225
17
r + m
1187
436
26
r + s
1078
463
48
r + h
876
3±8
20
r + h
83o
675
16
r + '
801
179
*4
r + d
768
1651
16
r+p
7<j3
1524
22
r + t
654
1744
8
r + t
587
151
17
412 The expected co-occurrence frequency (fc) is calculated by the following formula:
fc=(l-fa/s)3)*(l-fb/s)3)*s/3
( fa = total token-frequency of one consonant; fb = total token frequency of the other
consonant; s = 83436, i.e. the total number of consonants in the data base).
Example: The consonants s and h are attested 4520 and 976 times respectively in
our database (ISP appendix 1). Out of 83436/3 = 27812 words in our database, we
would expect (1 - 4520 / 83436)3) * (1 - 976 / 83436)3) * 83436 / 3 = 148 of them to
contain both 5 and h. However only three such words are attested. This indicates that
there is a strong restriction against the co-occurrence of s and h within a morpholog-
ically non-complex word.
297
The following charts are based on exactly the same data base which was counted in
appendix 1, with the same selections and corrections made. They show how often two
consonants co-occur within a word. I indicate:
a) the token-frequency (total number of words, i.e. word tokens, in which both conso-
nants occur at least once each) statistically to be expected according to the conso-
nant frequency indicated in appendix 1 under the assumption that the occurrence of
two consonants within a word were independent from each other412
b) the token-frequency actually attested
c) the a
ttested
type-frequency (number of different words in which both consonants
occur at least once each)
a)
b)
°)
»)
b)
<=)
*)
*>)
c)
j+j
2694
3n
±3
j + 71
2659
2421
"5
j + r
2181
2877
45
j + w
2095
1241
85
j + 1
i6o3
1255
76
j + m
1467
1126
65
j + s
±33a
665
71
j + h
1082
718
55
j + h
1025
340
22
/+'
989
39o
17
j + d
948
1547
11
J+P
869
1096
22
j + t
807
285
3i
j + t
726
5*6
36
j + k
7*4
1589
19
j+b
601
469
45
j + d
543
433
27
j + z
422
356
15
j+f
368
141
8
j + s
338
220
29
j + h
3oo
350
25
i + q
225
176
19
j + h
**■
125
9
i*n
144
127
11
n + n
2624
607
37
n + t
2152
2041
28
n + w
2068
1701
102
n + J
1582
75
26
n + m
M47
1128
68
n + s
i3i4
537
100
n + h
1068
949
61
n + h
1011
1126
65
n + c
976
1188
35
n + d
936
36o
29
n + p
857
114
24
n + t
797
1772
34
n +1
716
565
39
n + k
704
1523
19
n + b
593
364
57
n + d
536
191
3o
n + z
417
*75
17
n+f
364
379
29
n + s
334
144
33
n + h
296
125
26
n + q
222
76
16
n + h
*fl6
io3
M
n+g
142
40
11
r + r
1765
57
14
r + w
1696
1244
68
r + l
1298
225
17
r + m
1187
436
26
r + s
1078
463
48
r + h
876
3±8
20
r + h
83o
675
16
r + '
801
179
*4
r + d
768
1651
16
r+p
7<j3
1524
22
r + t
654
1744
8
r + t
587
151
17
412 The expected co-occurrence frequency (fc) is calculated by the following formula:
fc=(l-fa/s)3)*(l-fb/s)3)*s/3
( fa = total token-frequency of one consonant; fb = total token frequency of the other
consonant; s = 83436, i.e. the total number of consonants in the data base).
Example: The consonants s and h are attested 4520 and 976 times respectively in
our database (ISP appendix 1). Out of 83436/3 = 27812 words in our database, we
would expect (1 - 4520 / 83436)3) * (1 - 976 / 83436)3) * 83436 / 3 = 148 of them to
contain both 5 and h. However only three such words are attested. This indicates that
there is a strong restriction against the co-occurrence of s and h within a morpholog-
ically non-complex word.
297