




Der Text des ›Welschen Gastes‹ besteht aus paargereimten Versen. Die Ermittlung der Tendenzen in der Verwendung von Reimen gehört seit den Anfängen der Germanistik zum Pflichtprogramm im Vorfeld einer Textausgabe. Der Einsatz von Reimen gibt einerseits potenziell Auskunft über die dialektale Einordnung, andererseits gibt er Aufschluss über den Stil und die Kreativität des Dichters. Bereits Wilhelm Grimm hat 1825 zu seiner Abschrift des Cod. Pal. germ. 389 eigenhändig ein Reimverzeichnis angefertigt (Digitalisat). 1908 hat Friedrich Ranke mit Sprache und Stil im Wälschen Gast des Thomasin von Circlaria eine detaillierte Untersuchung der Reime im ›Welschen Gast‹ anhand der Rückert-Ausgabe vorgelegt.
Die bisherigen Untersuchungen leiden – zumindest was deren Relevanz für Erkenntnisse zur Sprache des Werkes angeht – an der methodischen Schwäche, dass sie vom sprachlich normalisierten Text der Rückert-Ausgabe ausgehen. Dabei liegt ein Zirkelschluss vor: Die Ausgabe Heinrich Rückerts normalisiert die Reime anhand einer vorgefassten Vorstellung von der Reimsprache des ›Welschen Gastes‹; die darauf basierenden Reimuntersuchungen kehren mit ihren Ergebnissen (zumindest teilweise) wieder zum Anfangspunkt – jener vorgefassten Vorstellung Heinrich Rückerts – zurück. Das ›Thomasin-Projekt‹ ist bestrebt, die transkribierten handschriftlichen Texte für Reimanalysen am ›Originalmaterial‹ fruchtbar zu machen. Reime werden auch als eine Eigenschaft der Texte betrachtet, die im editorischen Arbeitsprozess und in der Visualisierung direkt berücksichtigt wird, indem Reime im Text markiert werden und in Verspaaren angezeigt werden können (vgl. die Transkription von Cod. Pal. germ. 389 bei aktivierter Textdarstellungsoption ›Reime hervorheben‹). Künftig sollen bei der Visualisierung durch unterschiedliche Einfärbung auch verschiedene Reimtypen auf Benutzerwunsch angezeigt werden können. Bereits jetzt werden – allerdings ›nur‹ in der Rückert-Ausgabe – unreine Reime rot hervorgehoben (Beispiel bei aktivierter Textdarstellungsoption ›Reime hervorheben‹ in V. 33–34).
Die Markierung der Reime erfolgt bei Handschriftentranskriptionen wegen der beträchtlichen Schreibvarianz bisher manuell. Um vorläufige Reimstatistiken anhand der Rückert-Ausgabe erstellen zu können, bot sich der sprachlich standardisierte Text für eine automatisierte Markierung der Reime an. Wegen des vermuteten hohen Anteils unreiner Reime erschien es wenig sinnvoll, eine einfache Methode anzuwenden, bei der die jeweils übereinstimmenden Zeichenketten am Ende der beiden Verse innerhalb eines Verspaars als Reime markiert würden. Stattdessen wurden aufgrund einiger Textbeobachtungen folgende Regeln aufgestellt:
Bis auf einige Sonderfälle (etwa Wortkombinationen wie verlorn : erkorn und Hiate am Wortende) erwiesen sich diese Regeln in vorläufigen Tests als zutreffend. Da im sprachlich normalisierten Text Vokale und Konsonanten klar disambiguiert und damit Silben computerlinguistisch klar erkennbar sind, konnten die Regeln als Algorithmus in ein Skript implementiert werden, das die Markierung der Reime im gesamten Rückert-Text übernahm. In einem anschließenden Korrekturgang wurden die wenigen abweichenden Sonderfälle manuell nachkorrigiert.
Der so annotierte Text der Rückert-Ausgabe wurde anschließend aus verschiedenen Perspektiven analysiert. Das wichtigste Ergebnis ist dabei das digitale Reimwörterbuch mit aufschlussreichen Netzwerk-Visualisierungen. Darüber hinaus wurde eine Reihe an Statistiken und Übersichten erstellt, die im Folgenden präsentiert werden.
Der bereits von Friedrich Ranke festgestellte hohe Anteil unreiner Reime hat sich bestätigt:
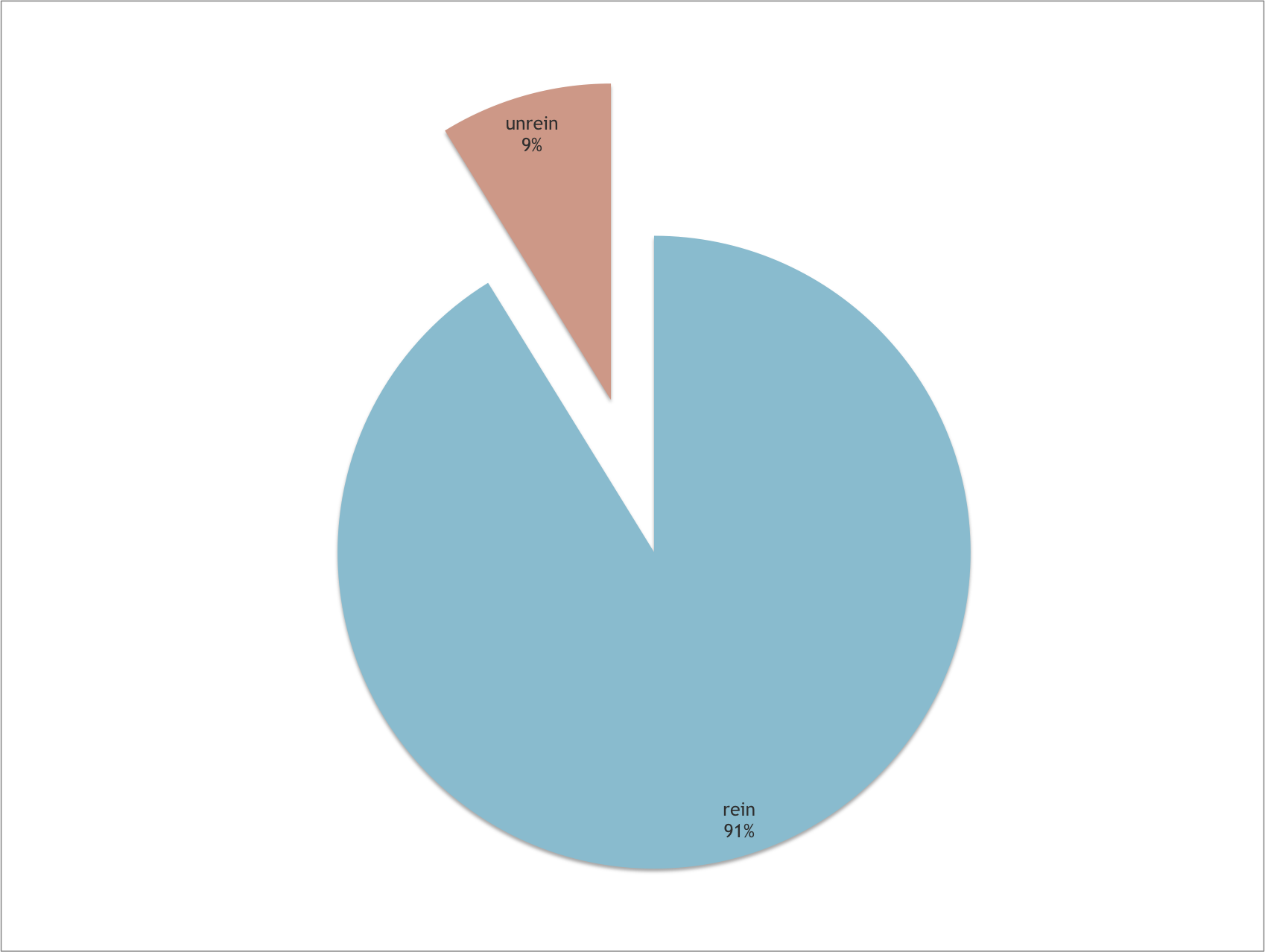 Anteil reiner und unreiner Reime (91,21% und 8,79%).
Anteil reiner und unreiner Reime (91,21% und 8,79%).
Aus der Anzahl der Textbelege (Verspaare) für einzelne Reime ergibt sich die folgende, absteigend sortierte Übersicht (aufgeführt sind Reime, die mehr als fünfmal vorkommen):
uot : uot (514-mal),
iht : iht (491-mal),
ol : ol (454-mal),
eit : eit (383-mal),
ist : ist (356-mal),
il : il (322-mal),
ât : ât (288-mal),
an : an (286-mal),
az : az (187-mal),
ît : ît (182-mal),
ar : âr (140-mal),
ân : ân (132-mal),
êre : êre (119-mal),
in : in (108-mal),
aft : aft (99-mal),
eben : eben (96-mal),
âr : ar (92-mal),
ot : ot (83-mal),
inne : inne (79-mal),
ære : ære (77-mal),
ar : ar (76-mal),
ant : ant (74-mal),
olde : olde (73-mal),
îche : îche (71-mal),
eht : eht (66-mal),
îchen : îchen (66-mal),
ac : ac (62-mal),
în : în (62-mal),
ehen : ehen (61-mal),
ugent : ugent (58-mal),
ôt : ôt (56-mal),
omen : omen (55-mal),
int : int (53-mal),
orn : orn (48-mal),
ân : an (47-mal),
unde : unde (45-mal),
esen : esen (44-mal),
ingen : ingen (44-mal),
art : art (43-mal),
unt : unt (41-mal),
uoz : uoz (41-mal),
îp : îp (40-mal),
eine : eine (32-mal),
ite : ite (32-mal),
agen : agen (30-mal),
er : êr (28-mal),
ulde : ulde (27-mal),
aht : aft (26-mal),
arn : arn (25-mal),
an : ân (24-mal),
emen : emen (23-mal),
anc : anc (22-mal),
iben : iben (20-mal),
ider : ider (20-mal),
iute : iute (20-mal),
êr : er (18-mal),
îch : îch (18-mal),
alt : alt (17-mal),
as : as (17-mal),
elle : elle (17-mal),
innen : innen (17-mal),
achen : achen (16-mal),
al : al (15-mal),
æte : æte (15-mal),
ert : ert (15-mal),
enne : enne (15-mal),
erre : erre (15-mal),
ône : ône (14-mal),
ên : ên (13-mal),
êrt : ert (13-mal),
er : er (13-mal),
eil : eil (13-mal),
îben : îben (13-mal),
uoc : uoc (13-mal),
uote : uote (13-mal),
ür : ür (13-mal),
aht : aht (12-mal),
ert : êrt (12-mal),
ehte : ehte (12-mal),
îs : îs (12-mal),
ich : ich (12-mal),
ôz : ôz (12-mal),
olden : olden (12-mal),
ôren : ôren (11-mal),
ouch : ouch (11-mal),
ach : ach (10-mal),
echen : echen (10-mal),
în : î (10-mal),
üete : üete (10-mal),
ast : ast (9-mal),
êt : êt (9-mal),
en : enn (9-mal),
ende : ende (9-mal),
icke : icke (9-mal),
ier : ier (9-mal),
âze : âze (8-mal),
acht : aft (8-mal),
ære : êre (8-mal),
ebet : ebet (8-mal),
in : inn (8-mal),
ir : ir (8-mal),
olt : olt (8-mal),
âr : âr (7-mal),
âzen : âzen (7-mal),
aft : aht (7-mal),
ein : ein (7-mal),
inget : inget (7-mal),
allen : allen (6-mal),
ande : ande (6-mal),
eiz : eiz (6-mal),
îbe : îbe (6-mal),
îse : îse (6-mal),
ill : il (6-mal),
ilde : ilde (6-mal),
iep : iep (6-mal),
iesen : iesen (6-mal),
or : or (6-mal),
oubet : oubet (6-mal),
ouwen : ouwen (6-mal),
ûre : ûre (6-mal).
Aus der Anzahl der Textbelege (Verspaare) für einzelne Reimwortkombinationen ergibt sich die folgende,
absteigend sortierte Übersicht (aufgeführt sind Reimwortkombinationen, die mehr als zehnmal vorkommen):
wol : sol (223-mal),
sol : wol (215-mal),
ist : vrist (208-mal),
wil : vil (190-mal),
niht : geschiht (161-mal),
gar : wâr (114-mal),
guot : muot (114-mal),
man : kan (112-mal),
vil : wil (99-mal),
hât : rât (90-mal),
vrist : ist (86-mal),
muot : guot (77-mal),
daz : baz (73-mal),
baz : daz (72-mal),
wâr : gar (69-mal),
geschiht : niht (69-mal),
kan : man (53-mal),
guot : tuot (53-mal),
tuot : guot (44-mal),
tuot : muot (41-mal),
got : gebot (40-mal),
geben : leben (39-mal),
gît : zît (39-mal),
muot : tuot (39-mal),
mac : tac (38-mal),
geriht : niht (38-mal),
wolde : solde (37-mal),
solde : wolde (35-mal),
man : an (32-mal),
hân : getân (30-mal),
nôt : tôt (29-mal),
wîp : lîp (28-mal),
rât : hât (25-mal),
iht : niht (24-mal),
niht : bœsewiht (24-mal),
tôt : nôt (24-mal),
sunde : stunde (24-mal),
mêre : lêre (23-mal),
in : sin (22-mal),
ist : list (22-mal),
sin : gewin (20-mal),
lît : zît (19-mal),
bœsewiht : niht (19-mal),
sint : kint (19-mal),
minne : sinne (19-mal),
zît : gît (18-mal),
enwiht : niht (18-mal),
niht : siht (18-mal),
tugent : jugent (18-mal),
untugent : jugent (18-mal),
schulde : hulde (18-mal),
dar : gar (17-mal),
reht : sleht (17-mal),
sîn : schîn (17-mal),
lât : hât (16-mal),
leben : geben (15-mal),
zît : lît (15-mal),
niht : geriht (15-mal),
kint : sint (15-mal),
gebot : got (15-mal),
meisterschaft : kraft (14-mal),
sîn : mîn (14-mal),
niht : iht (14-mal),
dingen : misselingen (14-mal),
muoz : vuoz (14-mal),
liute : hiute (14-mal),
gar : schar (13-mal),
kneht : reht (13-mal),
herre : verre (13-mal),
rîche : gelîche (13-mal),
zorn : verlorn (13-mal),
übermuot : guot (13-mal),
tugenthaft : kraft (12-mal),
an : man (12-mal),
hart : vart (12-mal),
mêre : êre (12-mal),
êre : sêre (12-mal),
komen : vernomen (12-mal),
guot : übermuot (12-mal),
lân : getân (11-mal),
hât : gât (11-mal),
hêrschaft : kraft (11-mal),
maht : kraft (11-mal),
schar : gar (11-mal),
mêre : sêre (11-mal),
gegeben : leben (11-mal),
wesen : genesen (11-mal),
sin : in (11-mal),
nider : wider (11-mal),
site : mite (11-mal),
jugent : tugent (11-mal),
stunde : sunde (11-mal),
vuoz : muoz (11-mal).
Die Verwendung der Tonvokale in Verspaaren (konkrete Belege) weist im gesamten Text folgende Häufigkeiten vor:
i (1658-mal),
a (1294-mal),
o (766-mal),
â (599-mal),
uo (598-mal),
e (562-mal),
î (501-mal),
ei (451-mal),
u (212-mal),
ê (191-mal),
æ (111-mal),
ô (110-mal),
ie (48-mal),
ou (37-mal),
iu (27-mal),
ü (20-mal),
üe (20-mal),
œ (10-mal),
û (10-mal),
ö (1-mal),
ŷ (1-mal).
 Anzahl der Verspaarbelege für Tonvokale im Gesamttext.
Anzahl der Verspaarbelege für Tonvokale im Gesamttext.
Einzelne Tonvokale weisen eine unterschiedliche Reimdiversität auf (absteigend sortierte Liste):
e: 82 verschiedene Reime
a: 71 verschiedene Reime
i: 56 verschiedene Reime
u: 26 verschiedene Reime
î: 23 verschiedene Reime
â: 22 verschiedene Reime
o: 20 verschiedene Reime
uo: 17 verschiedene Reime
ie: 16 verschiedene Reime
ê: 14 verschiedene Reime
ei: 14 verschiedene Reime
ô: 13 verschiedene Reime
æ: 11 verschiedene Reime
ou: 10 verschiedene Reime
üe: 9 verschiedene Reime
ü: 7 verschiedene Reime
œ: 6 verschiedene Reime
iu: 6 verschiedene Reime
û: 3 verschiedene Reime
ö: 1 Reim
ŷ: 1 Reim.
 Anzahl unterschiedlicher Reime pro Tonvokal.
Anzahl unterschiedlicher Reime pro Tonvokal.
Einzelne Tonvokale weisen eine unterschiedliche Diversität zugeordneter Reimwortkombinationen auf (absteigend sortierte Liste):
a: 413 verschiedene Reimwortkombinationen
ei: 331 verschiedene Reimwortkombinationen
i: 289 verschiedene Reimwortkombinationen
e: 273 verschiedene Reimwortkombinationen
î: 228 verschiedene Reimwortkombinationen
â: 165 verschiedene Reimwortkombinationen
uo: 103 verschiedene Reimwortkombinationen
o: 87 verschiedene Reimwortkombinationen
æ: 80 verschiedene Reimwortkombinationen
ê: 78 verschiedene Reimwortkombinationen
u: 77 verschiedene Reimwortkombinationen
ô: 36 verschiedene Reimwortkombinationen
ie: 32 verschiedene Reimwortkombinationen
ou: 17 verschiedene Reimwortkombinationen
üe: 17 verschiedene Reimwortkombinationen
œ: 9 verschiedene Reimwortkombinationen
ü: 9 verschiedene Reimwortkombinationen
iu: 9 verschiedene Reimwortkombinationen
û: 8 verschiedene Reimwortkombinationen
ö: 1 Reimwortkombination
ŷ: 1 Reimwortkombination
 Anzahl unterschiedlicher Reimwortkombinationen pro Tonvokal.
Anzahl unterschiedlicher Reimwortkombinationen pro Tonvokal.
Sehr große Unterschiede gibt es beim Reimwortreichtum einzelner Reime. Die nachfolgende Liste zeigt die Anzahl verschiedener
Reimwortkombinationen pro Reim an (absteigend sortiert; nur Reime, die mehr
als fünf Reimwortkombinationen aufweisen):
eit : eit (285),
ât : ât (69),
uot : uot (63),
îchen : îchen (58),
iht : iht (53),
ære : ære (50),
ant : ant (49),
ît : ît (45),
îche : îche (42),
aft : aft (38),
ân : ân (37),
an : an (31),
inne : inne (28),
ehen : ehen (25),
agen : agen (24),
în : în (23),
in : in (23),
az : az (21),
êre : êre (21),
art : art (20),
eine : eine (20),
ingen : ingen (20),
unt : unt (20),
ân : an (19),
ar : ar (19),
orn : orn (19),
eben : eben (18),
ist : ist (18),
anc : anc (17),
îch : îch (17),
il : il (17),
er : êr (16),
eht : eht (14),
ert : ert (14),
omen : omen (14),
as : as (13),
int : int (13),
ot : ot (13),
esen : esen (12),
alt : alt (11),
æte : æte (11),
êr : er (11),
ol : ol (11),
ac : ac (10),
al : al (10),
an : ân (10),
ar : âr (10),
ên : ên (10),
êrt : ert (10),
ert : êrt (10),
uoz : uoz (10),
achen : achen (9),
echen : echen (9),
unde : unde (9),
âr : ar (8),
aht : aft (8),
arn : arn (8),
ære : êre (8),
er : er (8),
elle : elle (8),
ende : ende (8),
enne : enne (8),
ich : ich (8),
iben : iben (8),
innen : innen (8),
ite : ite (8),
uoc : uoc (8),
üete : üete (8),
ach : ach (7),
êt : êt (7),
eil : eil (7),
îben : îben (7),
âze : âze (6),
aht : aht (6),
ande : ande (6),
ehte : ehte (6),
emen : emen (6),
ôz : ôz (6),
ône : ône (6),
ôren : ôren (6),
ugent : ugent (6),
uote : uote (6).
 Anzahl unterschiedlicher Reimwortkombinationen pro Reim.
Anzahl unterschiedlicher Reimwortkombinationen pro Reim.
Auch einzelne Teile des Textes unterscheiden sich erheblich in der Diversität von Reimen und Reimwortkombinationen. Je höher die Werte in den folgenden Tabellen und im Diagramm, desto reimreicher ist ein Teil des Werkes. Es liegt eine gewisse Verzerrung durch die unterschiedliche Länge der einzelnen Textteile vor, doch dadurch wird die Grundtendenz nur markanter.
Anzahl unterschiedlicher Reime pro Textteil:
| Versvorrede | Buch 1 |
Buch 2 |
Buch 3 |
Buch 4 |
Buch 5 |
Buch 6 |
Buch 7 |
Buch 8 |
Buch 9 |
Buch 10 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|
| 34 | 165 | 137 | 150 | 112 | 120 | 141 | 143 | 175 | 101 | 101 | |
Anzahl unterschiedlicher Reimwortkombinationen pro Textteil:
| Versvorrede | Buch 1 |
Buch 2 |
Buch 3 |
Buch 4 |
Buch 5 |
Buch 6 |
Buch 7 |
Buch 8 |
Buch 9 |
Buch 10 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|
| 55 | 424 | 295 | 410 | 356 | 284 | 452 | 392 | 632 | 337 | 284 | |
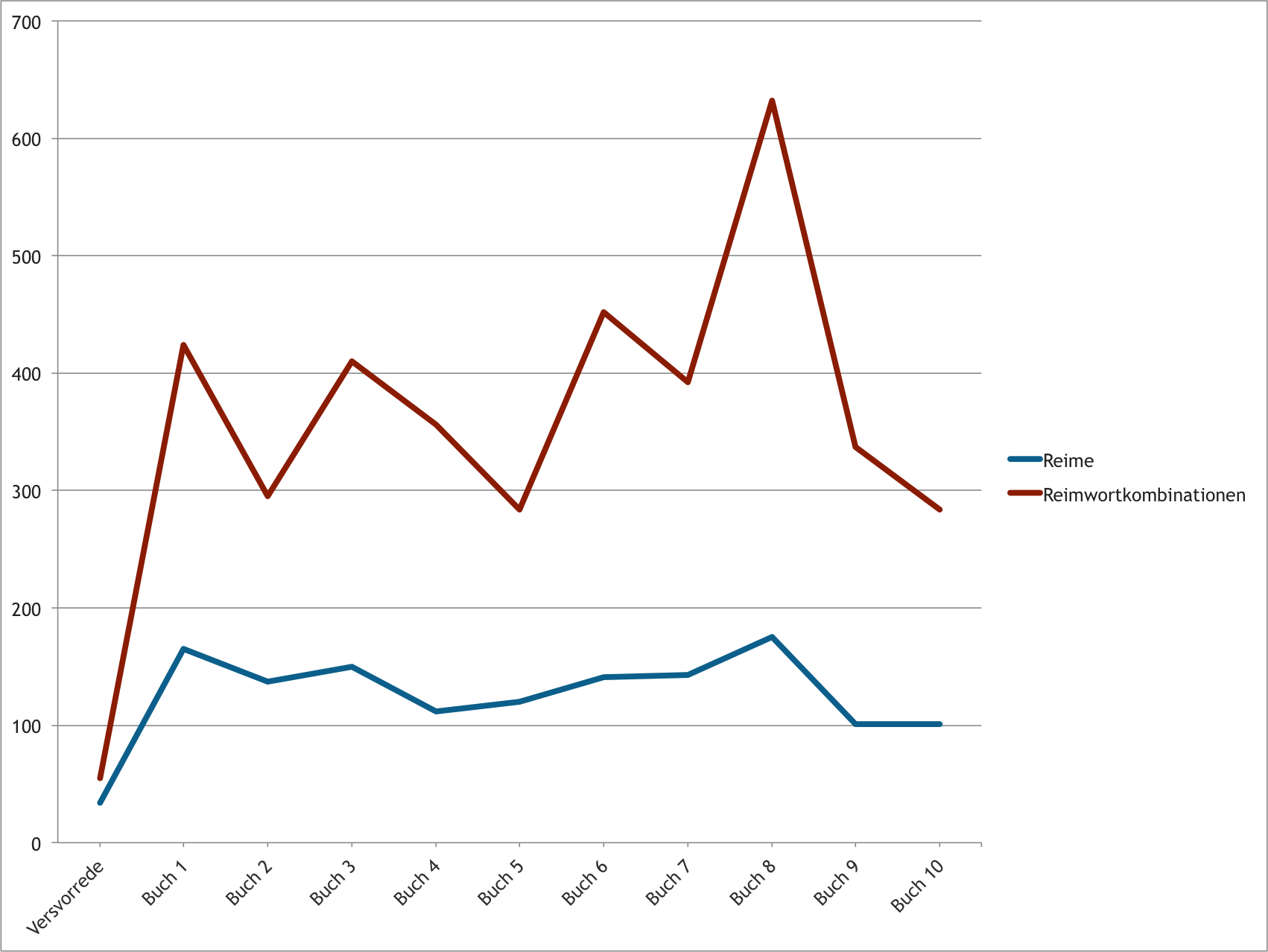 Anzahl unterschiedlicher Reime und Reimwortkombinationen in einzelnen Teilen des Textes.
Anzahl unterschiedlicher Reime und Reimwortkombinationen in einzelnen Teilen des Textes.
Diese Tendenzen wurden ebenfalls an der prozentuellen Vertretung der insgesamt häufigsten Reime und Reimwörter in einzelnen Textteilen überprüft. Dort ist die Ausrichtung der Kurve genau umgekehrt zu interpretieren: Je höher der Anteil der insgesamt häufigsten Reime und Reimwortkombinationen, umso reimärmer ist der Textteil.
| Versvorrede | Buch 1 |
Buch 2 |
Buch 3 |
Buch 4 |
Buch 5 |
Buch 6 |
Buch 7 |
Buch 8 |
Buch 9 |
Buch 10 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|
| uot : uot | 2,9 | 8,4 | 3,2 | 9,8 | 8,2 | 8,5 | 6,6 | 4,6 | 6,9 | 5,8 | 6,2 |
| iht : iht | 8,6 | 6,3 | 6,6 | 5,9 | 9,4 | 6,7 | 6,0 | 5,1 | 4,5 | 9,5 | 8,2 |
| ol : ol | 12,9 | 6,6 | 3,2 | 4,2 | 7,2 | 6,9 | 5,0 | 6,1 | 4,3 | 10,3 | 8,2 |
| eit : eit | 1,4 | 6,3 | 4,6 | 4,8 | 6,3 | 3,8 | 5,7 | 6,7 | 5,2 | 3,4 | 4,4 |
| ist : ist | 4,3 | 2,7 | 5,1 | 5,2 | 6,3 | 5,2 | 5,0 | 3,9 | 4,4 | 3,6 | 7,7 |
| il : il | 5,7 | 4,6 | 4,6 | 6,3 | 4,1 | 4,2 | 2,6 | 1,7 | 5,3 | 4,3 | 5,2 |
| ât : ât | 4,3 | 3,1 | 5,4 | 4,1 | 3,1 | 3,1 | 3,3 | 3,8 | 3,4 | 6,6 | 4,5 |
| an : an | 10,0 | 5,4 | 1,2 | 5,2 | 5,6 | 3,4 | 3,2 | 4,6 | 3,0 | 2,7 | 2,5 |
| az : az | 0,0 | 2,1 | 1,7 | 1,6 | 3,2 | 3,6 | 3,0 | 1,9 | 1,9 | 4,0 | 3,0 |
| ît : ît | 1,4 | 1,2 | 2,7 | 1,2 | 1,2 | 2,2 | 3,3 | 0,9 | 2,6 | 2,2 | 8,4 |
| Versvorrede | Buch 1 |
Buch 2 |
Buch 3 |
Buch 4 |
Buch 5 |
Buch 6 |
Buch 7 |
Buch 8 |
Buch 9 |
Buch 10 |
|
|---|---|---|---|---|---|---|---|---|---|---|---|
| wol : sol | 10,0 | 3,6 | 1,2 | 2,1 | 4,0 | 4,2 | 2,3 | 3,0 | 2,4 | 4,2 | 2,5 |
| sol : wol | 2,9 | 3,0 | 1,5 | 2,0 | 3,0 | 2,5 | 2,5 | 2,8 | 1,8 | 6,1 | 4,9 |
| ist : vrist | 0,0 | 1,2 | 2,9 | 3,0 | 4,0 | 2,7 | 3,5 | 2,5 | 2,4 | 2,4 | 4,4 |
| wil : vil | 1,4 | 2,2 | 1,7 | 2,6 | 3,2 | 2,9 | 1,9 | 0,9 | 2,9 | 3,7 | 3,7 |
| niht : geschiht | 2,9 | 1,4 | 4,4 | 3,1 | 4,0 | 2,5 | 1,6 | 1,6 | 1,5 | 0,9 | 2,0 |
| gar : wâr | 0,0 | 0,8 | 0,7 | 1,2 | 0,9 | 2,4 | 1,2 | 1,4 | 1,9 | 2,7 | 2,4 |
| guot : muot | 0,0 | 2,4 | 0,7 | 2,6 | 1,4 | 2,0 | 1,8 | 2,0 | 0,7 | 0,1 | 1,9 |
| man : kan | 5,7 | 2,3 | 0,5 | 1,7 | 2,3 | 1,4 | 1,4 | 1,6 | 1,2 | 0,9 | 0,8 |
| vil : wil | 4,3 | 1,7 | 2,4 | 2,1 | 0,6 | 1,3 | 0,6 | 0,7 | 1,9 | 0,6 | 1,3 |
| hât : rât | 1,4 | 1,7 | 1,0 | 1,2 | 0,4 | 1,1 | 1,3 | 1,7 | 1,3 | 1,2 | 1,0 |
Die folgenden beiden Diagramme zeigen die Daten der vorausgehenden beiden Tabellen. Die dicke rote Kurve visualisiert jeweils die Durchschnittswerte aller zehn Reime bzw. Reimwortkombinationen.
 Prozentuelle Vertretung der zehn häufigsten Reime in einzelnen Teilen des Textes.
Prozentuelle Vertretung der zehn häufigsten Reime in einzelnen Teilen des Textes.
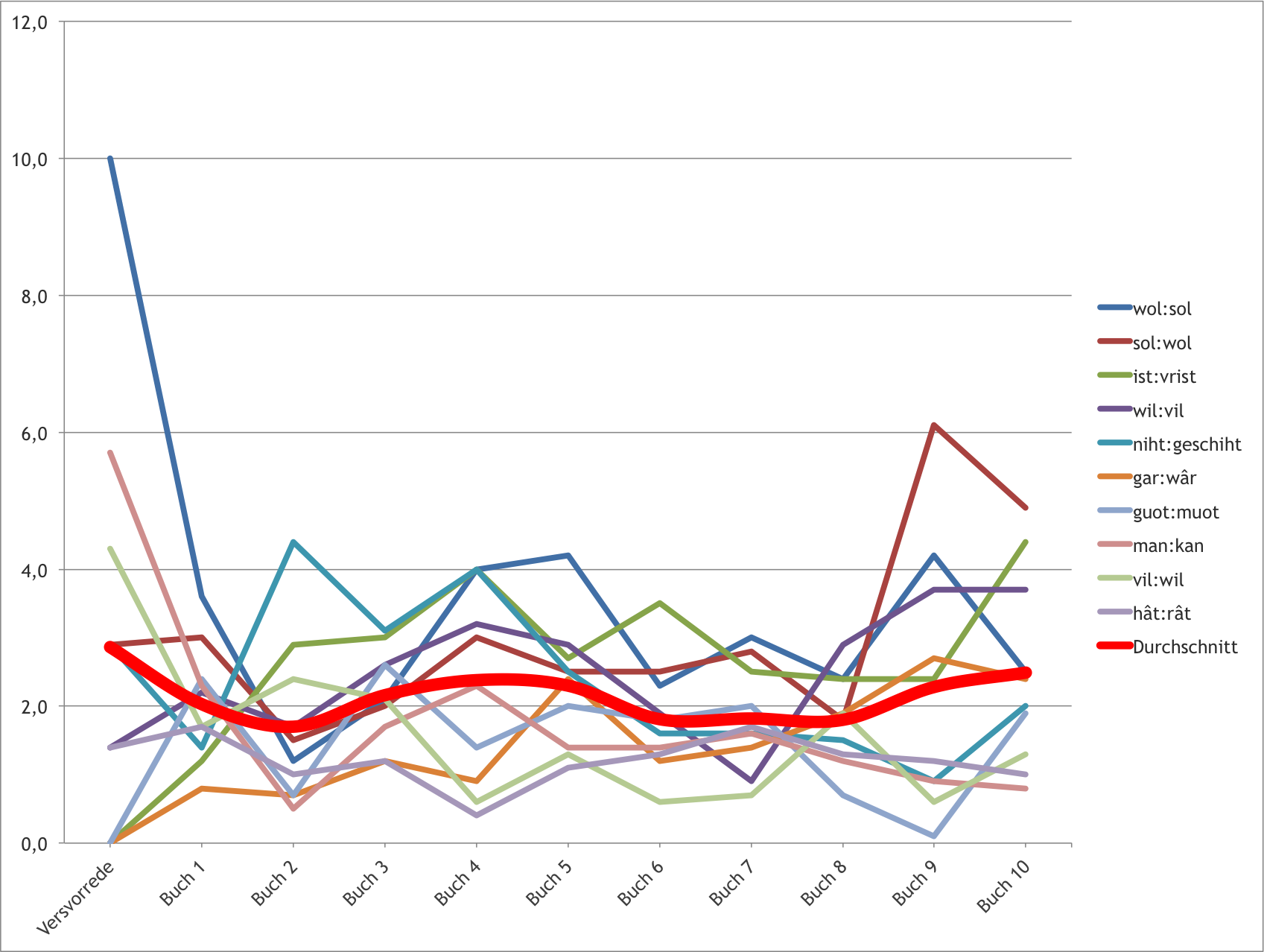 Prozentuelle Vertretung der zehn häufigsten Reimwortkombinationen in einzelnen Teilen des Textes.
Prozentuelle Vertretung der zehn häufigsten Reimwortkombinationen in einzelnen Teilen des Textes.
